
Deep Learning wird inzwischen in vielen Bereichen gewinnbringend verwendet. Einer dieser Bereiche ist das Modellieren von Sequenzen. Sequenzmodellierung ist die Fähigkeit eines Programms sequentielle Daten zu interpretieren. Bekannt ist dieser Bereich vor allem für Chatbots und der Übersetzung von Sprachen (Neural Machine Translation). Hier wurden in den letzten Jahren erstaunliche Fortschritte gemacht.
Weniger bekannt ist jedoch, dass fast dieselben Architekturen von Modellen auch auf Zeitreihen angewendet werden können. Also beispielsweise das Vorhersagen von Verkaufszahlen, Aktienkursen oder dem Wetter. Wie so etwas aussehen kann, wird im Weiteren an einem Beispiel erläutert.
Das Benzinpreis-Dilemma
Wer kennt es nicht? Kaum ist man an einer Tankstelle angekommen, so liegt der Benzinpreis schon wieder deutlich höher als die letzten Male. Überprüft man per Smartphone-App die Preise nahegelegener Tankstellen, so stellt man schnell fest: Die Preise sind genauso hoch! Hätte man doch gestern getankt.
Abhilfe schaffen lässt sich durch das Vorhersagen der Benzinpreise. Glücklicherweise sind alle Tankstellenbetreiber seit ein paar Jahren verpflichtet sämtliche Preisänderungen dem Bundeskartellamt zu melden. Die Daten sind also erhältlich. Und zahlreich!
In dem vorherigen Blog-Beitrag “Wie sich die Benzinpreise in Deutschland entwickeln” haben wir die Benzinpreise der letzten Jahre in Deutschland analysiert. Laut den Analysen lohnt es sich darüber nachzudenken, wann und wo man tanken sollte.
Welche verschiedenen Arten für die Vorhersage von Sequenzen gibt es?
Zur Lösung des Anwendungsfalles stellt sich die Frage, um welche Art von Sequenzmodellierung es sich handelt. Denn Benzinpreise sind offensichtlich Zeitreihendaten und damit Sequenzen. Um diese vorherzusagen müssen sie modelliert werden. Die Modellierung von Sequenzen lässt sich generell in 3 Bereiche unterteilen.
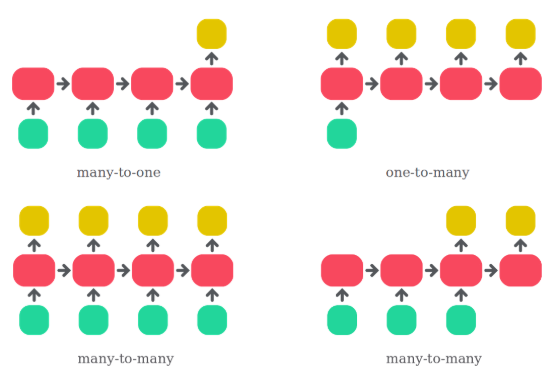
- Bei der many-to-one Sequenzmodellierung wird mithilfe einer Sequenz eine einzelne Ausgabe vorhergesagt. Zum Beispiel werden die Wörter eines Textes nacheinander eingelesen und anschließend bewertet, ob die Aussage des Textes positiv oder negativ ist. Dieser Problemfall wird als Sentimentanalyse bezeichnet und gern in der Marktforschung verwendet.
- Bei der one-to-many Sequenzmodellierung wird eine Sequenz mithilfe einer einzelnen Eingabe generiert. Ein solcher Use-Case ist das Erzeugen eines Textes, der beschreibt, was auf einem Bild dargestellt ist.
- Die many-to-many Sequenzmodellierung beschreibt die Generierung einer Sequenz mithilfe einer Eingabesequenz. Dieser Bereich lässt sich weiter in zwei Unterbereiche unterteilen.
- Die Länge der Eingabe- und der Ausgabesequenz sind identisch: Ein Beispiel hierfür ist Named Entity Recognition. Dabei wird mittels eines Textes ermittelt, ob es sich bei einer Folge von Wörtern um einen Eigennamen handelt.
- Die Länge der Eingabe und der Ausgabesequenz können verschieden sein. Hierzu gehören Chatbots und Neural Machine Translation.
Wie sieht die Lösung konkret aus?
Bei dem zuvor erwähnten Anwendungsfall mit den Benzinpreisen handelt es sich um ein many-to-many Problem. Die stündlichen Benzinpreise einer Tankstelle von einer beliebigen Anzahl an Tagen werden als Eingabesequenz verwendet. Anschließend wird eine Vorhersage für die stündlichen Benzinpreise des nächsten Tages oder der nächsten Tage ermittelt.
Verwendet wurde eine sogenannte Encoder-Decoder Architektur. Vorteilhaft an dieser Architektur ist vor allem, dass man sich nicht auf eine bestimmte Länge der Ausgabesequenz beschränken muss. Die Encoder-Decoder Architektur gilt mit verschiedenen Erweiterungen heutzutage als State-of-the-Art in vielen Bereichen.
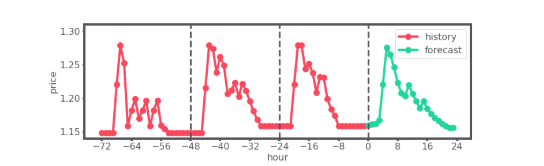
Stündliche Dieselpreise einer Tankstelle über drei Tage, die als Eingabesequenz verwendet wurden. Außerdem ist die Vorhersage der Preise für einen weiteren Tag dargestellt.
Bereits mit einer sehr simplen Encoder-Decoder Architektur lassen sich Benzinpreise für den nächsten Tag vorhersagen, die im Mittel eine Genauigkeit von fast einem Cent erreichen. Die Möglichkeiten, das Modell nachfolgend zu erweitern und zu verbessern, sind zahlreich.
In einem nachfolgenden Beitrag werden wir erläutern wie die beschriebene Encoder-Decoder Architektur im Detail funktioniert. Außerdem werden wir genauer darauf eingehen wie unsere Lösung aussieht.

